开发者转向 AI 应用工程:真正要迁移的是工程判断力
开发者不必转算法岗,真正需要的是将软件工程经验迁移到AI应用开发中,解决模型不确定性带来的工程挑战。核心内容:1. AI应用开发中的常见工程问题2. 传统软件工程经验如何迁移3. 开发者转向AI应用工程的核心能力
很多开发者看见 AI 应用开发,第一反应是:
是不是要转算法岗?
是不是要重新学训练框架、论文、微调、分布式训练?
这些当然都是重要能力。
但对大多数正在做业务系统、后端服务、前端产品、测试平台和工程交付的人来说,真正更现实的转向不是“从零变成算法研究员”。
而是把已有的工程判断力,迁移到 AI 应用这种新系统上。
这篇作为 AIGuide 输出式学习系列的收束篇,想讲一个判断:
AI 应用工程不是抛弃软件工程经验,而是升级它。
先看一个很普通的需求。
产品说:我们想做一个智能客服。
第一版很快。
接一个模型 API,写一段 prompt,放几份 FAQ,前端加个聊天框。
Demo 看起来已经能用了。
但只要它开始面对真实用户,问题马上变得熟悉起来:
- • 用户问法不可控
- • 模型回答不稳定
- • FAQ 更新后旧答案还在
- • 有些问题需要查订单、查权限、查工单
- • 一次回答失败后要不要重试
- • 多个模型供应商怎么切
- • 用户数据能不能进入 prompt
- • 成本突然升高算到哪个功能头上
- • 线上事故怎么回滚
- • 这个回答到底算不算正确
这些问题看起来是 AI 问题。
但你仔细看,会发现它们又非常像传统软件工程问题。
接口、缓存、消息、数据库、网关、日志、指标、权限、测试、发布、回滚。
只是现在,中间多了一个大模型。
这个模型能力很强,但不确定性也很强。
它能生成自然语言,能理解上下文,能调用工具,能参与写代码。
但它也会漂,会忘,会幻觉,会受上下文影响,会把成本藏在 token 里。
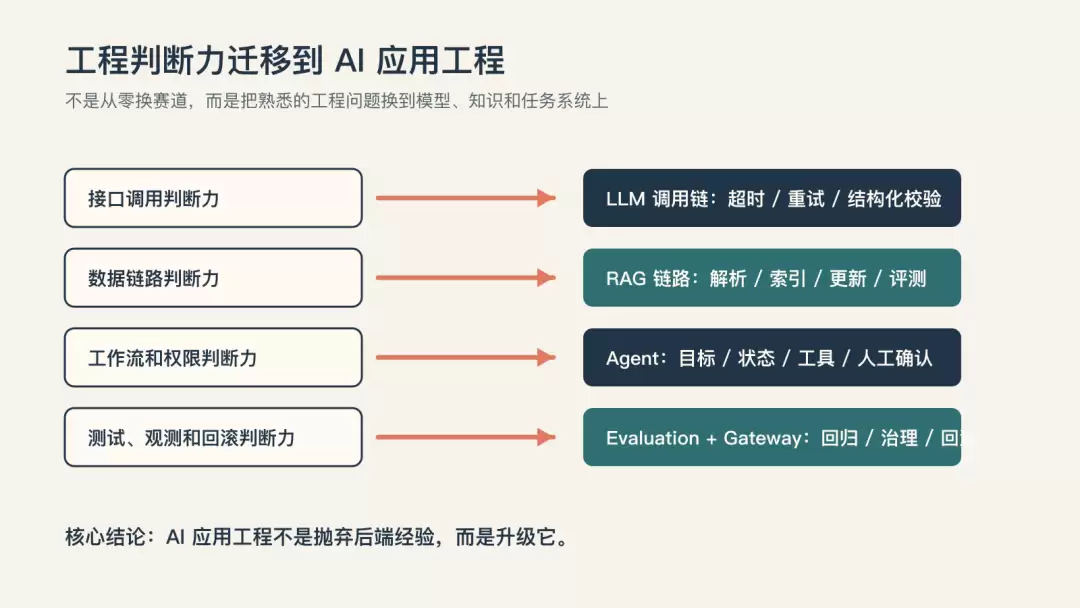
所以开发者转向 AI 应用工程,真正要迁移的不是某一个框架 API。
而是你过去在工程里练出来的判断力。
一、别把 AI 应用开发误解成“转算法岗”
AIGuide 里有一个很值得保留的定位。
它不是只给算法同学看的。
它面向的是后端、前端、测试、架构师、技术管理者和产品技术同学。
这点很重要。
因为现在很多开发者一听 AI 应用开发,就会自动脑补成另一条路:
先学数学。
再学深度学习。
再学训练框架。
再看论文。
最后才能做 AI 项目。
这条路当然存在。
但它不是所有人进入 AI 应用工程的唯一入口。
如果你的目标是训练基础模型、做算法研究、做模型架构优化,那确实需要很深的算法和训练能力。
但如果你的目标是把 AI 放进真实产品、真实业务系统、真实研发流程里,你首先要面对的是另一组问题:
- • 模型调用链路怎么设计
- • 私有知识怎么进入模型
- • 工具调用怎么控权限
- • 长任务状态怎么保存
- • 回答质量怎么评测
- • 多模型怎么路由和降级
- • 成本怎么归因
- • 线上行为怎么观测
- • 出错以后怎么回滚
这些问题不是靠背几篇论文就能解决。
它们更接近工程。
也正因为如此,普通开发者不是没有优势。
你过去做接口设计、系统重构、数据库优化、消息队列、缓存一致性、灰度发布、线上排障、CI/CD、代码 review 的经验,都可以迁移过来。
AI 应用工程不是另起炉灶。
它是在软件系统里接入一个新型能力层。
二、LLM API 仍然是一条服务调用链
很多 AI 项目的第一步,是调用模型。
这一步很容易让人产生错觉。
因为模型 API 看起来太像聊天框了。
传一段 messages,返回一段 answer。
于是团队很容易把它当成“更聪明的字符串函数”。
但真正进系统以后,它仍然是一条服务调用链。
服务调用链就会有老问题:
- • 超时
- • 重试
- • 限流
- • 取消
- • 幂等
- • 降级
- • 日志
- • 监控
- • 费用
- • 错误分类
只不过这条链路多了一些 AI 特有问题:
- • 上下文窗口会被截断
- • 采样参数会影响稳定性
- • JSON 可能不合法
- • Function Calling 可能选错工具
- • 流式输出中途可能断开
- • 同一个 prompt 在不同模型上表现不同
- • token 成本需要单独记录
这时候,一个有经验的后端开发者会自然地问:
这个调用有没有超时策略?
返回结构在哪里校验?
失败以后是重试、fallback,还是直接报错?
用户取消请求时,后端有没有中断下游调用?
模型返回半截内容时,状态怎么处理?
这些问题一点也不“AI 炫技”。
但它们决定了 AI 功能能不能进生产。
所以,学习 LLM API 的时候,不要只学“怎么调通”。
要把它看成一条新型 RPC。
调用对象不是数据库,不是搜索服务,不是支付网关,而是模型。
但工程纪律没有消失。
三、RAG 最像数据工程,不是向量库采购
第二个容易被误解的是 RAG。
很多人一提 RAG,马上想到向量数据库。
选 Milvus 还是 pgvector?
Embedding 用哪个模型?
相似度阈值设多少?
这些当然重要。
但 RAG 在真实项目里更像一条数据工程链路。
你要先回答:
文档从哪里来?
PDF、网页、表格、图片、Markdown、工单、会议纪要,怎么解析?
脏数据怎么清洗?
Chunk 怎么切?
元数据怎么保留?
文档更新以后怎么增量同步?
旧版本怎么下线?
用户问法变化时,query 要不要改写?
关键词检索和向量检索怎么混合?
召回结果要不要 rerank?
答案引用怎么追溯到原文?
RAG 答非所问时,很多团队第一反应是换模型。
但工程上更靠谱的做法,是先排查链路。
是不是文档没解析好?
是不是 Chunk 切得太粗?
是不是召回到了相似但不相关的段落?
是不是缺了关键词检索?
是不是上下文组织把关键材料挤掉了?
这就很像传统数据系统。
一个报表算错,不一定是数据库不行。
可能是 ETL 错了,字段口径错了,维表没更新,数据延迟,或者查询条件写偏了。
RAG 也是一样。
向量库只是中间一环。
真正的工程能力,是能把知识进入模型这条链路拆开、观测、评测、修复。

四、Agent 最需要的不是自由,而是责任边界
Agent 是最容易让人兴奋的一层。
因为它看起来终于不是“问一句答一句”了。
它能规划。
能调工具。
能读文件。
能查资料。
能写代码。
能循环推进任务。
但从工程角度看,Agent 越能做事,越要问责任边界。
一个 Agent 能不能删文件?
能不能发邮件?
能不能改数据库?
能不能调用付款接口?
能不能把用户隐私放进第三方模型?
能不能绕过测试直接提交代码?
这些都不是模型能力问题。
这是权限、审计、状态和人工确认问题。
在传统系统里,一个服务能做什么,通常由接口权限、角色、配置、审批流和审计日志控制。
Agent 也一样。
只不过它的行动空间更大。
如果不设计边界,它可能会用看似合理的方式把任务推进到危险位置。
所以,Agent 工程里最重要的不是“让它更自由”。
而是让它在合适的边界内持续推进。
它要知道:
- • 目标是什么
- • 哪些工具能用
- • 哪些数据不能碰
- • 中间状态保存在哪里
- • 失败以后怎么恢复
- • 哪些节点必须等人确认
- • 最后要留下什么轨迹供 review
这和我们过去做工作流、审批、任务系统、CI/CD 很像。
区别在于,以前流程节点大多是确定代码。
现在节点里多了模型判断。
模型判断可以提升效率,也会放大不确定性。
因此更需要工程结构兜住。
五、Context Engineering 是新的信息架构能力
Prompt Engineering 曾经是很多人学习 AI 的入口。
但越往后做,越会发现 prompt 只是其中一小块。
真正影响模型输出的,是它在这次调用前看见了什么。
项目规则。
用户目标。
历史状态。
检索材料。
工具结果。
错误日志。
验收标准。
安全限制。
这些东西怎么组织,决定了模型表现。
所以 Context Engineering 其实很像新的信息架构能力。
开发者要判断:
哪些信息应该常驻?
哪些应该按需加载?
哪些应该只保留摘要?
哪些应该用结构化格式给模型?
哪些过期信息应该移出上下文?
哪些约束应该写进项目规则,哪些只该放在本次任务里?
这和传统工程里的配置、文档、缓存、状态管理并不陌生。
只是对象变了。
以前我们给人组织信息。
现在还要给模型组织信息。
如果上下文太少,模型会缺关键事实。
如果上下文太多,模型会被噪声稀释。
如果上下文过期,模型会沿着旧状态继续错。
如果上下文没有结构,模型会把重要约束当成普通背景。
所以,学 AI 应用工程不能只学 prompt 技巧。
真正要练的是:
在有限 token 预算里,把当前任务最该看的信息放到最清楚的位置。
六、评测和网关,是 demo 到生产的分水岭
一个 demo 能跑,不代表一个 AI 应用能上线。
这句话对所有工程系统都成立。
AI 应用只是更明显。
因为它的输出不像传统函数那样稳定。
传统接口如果返回错,通常可以用断言、单测、集成测试、日志和错误码定位。
AI 输出错的时候,团队经常只剩一句话:
感觉不太对。
这就是评测要解决的问题。
你需要 Golden Set。
需要 LLM-as-Judge。
需要人工抽检。
需要 Trace 回放。
需要 RAG 召回评测。
需要 Agent 过程指标。
需要把关键样本放进 CI 或发布前回归。
评测不是给 AI 打个分。
评测是 AI 应用的回归系统。
同样,网关也不是锦上添花。
只要 AI 功能接入业务流量,就会遇到:
- • 多模型供应商
- • 模型路由
- • fallback
- • 限流
- • Token 预算
- • 成本归因
- • 缓存
- • 审计
- • 安全策略
- • 数据隔离
这些问题不解决,AI 功能就会停在“能演示”。
解决了,才有机会进入“能运营”。
所以我会把评测和网关看成生产分水岭。
前者回答:这个系统质量能不能被持续判断。
后者回答:这个系统运行能不能被持续治理。
七、AI Coding 也在考验同一套工程判断力
AIGuide 还有一条很重要的支线:AI Coding。
Claude Code、Codex、Cursor、Trae、Qoder,各种工具越来越强。
但真正拉开差距的,常常不是“哪个工具最强”。
而是开发者怎么用它。
同一个模型,有人用来让它一口气改几百行代码,然后自己在 diff 里迷路。
有人会先写清楚任务范围,再给相关文件,再让它小步修改,再跑测试,再 review,再提交。
结果完全不一样。
AI Coding 表面看是写代码。
底层还是研发流程。
你要判断:
- • 这个任务适合交给 CLI 还是 IDE
- • 现在该让 AI 写代码,还是先让它读代码
- • 任务范围能不能再拆小一点
- • 哪些上下文必须给,哪些会干扰
- • 测试应该先补还是后补
- • diff 有没有越界
- • 提交是不是可回滚
- • 失败以后应该继续修,还是回退到上一步
这些判断,都是工程判断力。
AI 没有让它们消失。
AI 只是让它们更早、更频繁、更集中地出现。
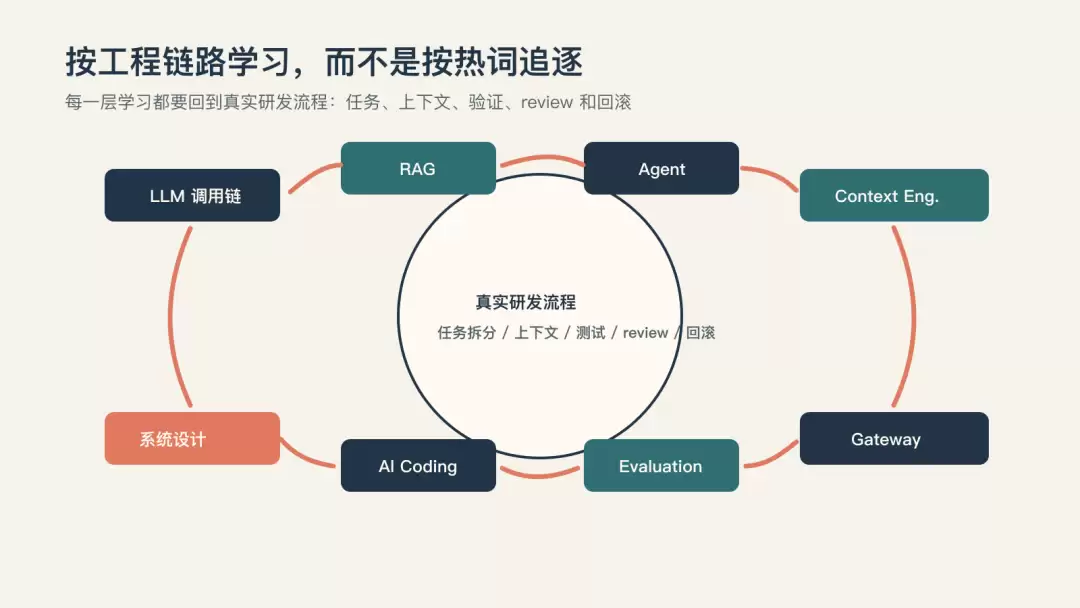
八、下一步怎么学:按工程链路补齐,不按热词追逐
如果你是普通开发者,想系统转向 AI 应用工程,我建议不要按热词追。
不要今天学一点 RAG,明天学一点 Agent,后天看一个 MCP,过几天又被新工具带走。
更好的方式,是按工程链路补齐。
第一步,学 LLM 调用链。
理解 token、上下文窗口、采样参数、结构化输出、Function Calling、流式响应、超时、重试和服务端校验。
第二步,学 RAG。
不要只学向量库,要学文档解析、切分、索引、混合检索、rerank、知识库更新和 RAG 评测。
第三步,学 Agent。
不要只看工具调用,要理解目标、状态、记忆、权限、人工确认、失败恢复和 trace。
第四步,学 Context Engineering。
把 prompt、项目规则、检索材料、工具结果、历史状态和验收标准放进同一个信息供给系统里看。
第五步,学 Evaluation。
从 Golden Set、Trace 回放、LLM-as-Judge、人工抽检、CI 回归和灰度开始,把体感改成可重复判断。
第六步,学 Gateway 和系统设计。
补齐多模型路由、fallback、限流、配额、成本、审计、安全和可观测。
第七步,学 AI Coding。
不是为了让 AI 替你写完所有代码,而是把任务拆分、上下文、测试、review 和回滚重新组织起来。
这条路线看起来长。
但它有一个好处:
每一步都能连接你已有的软件工程经验。
你不是从零开始。
你是在把旧能力迁移到新对象上。
九、收束一下:AI 应用工程的主角仍然是工程
回到这个系列的第一篇。
我当时说,学 AI 应用开发,别只背概念。
写到第 10 篇,判断其实更明确了:
学 AI 应用工程,也别只追工具。
工具会换。
模型会换。
框架会换。
但一些判断不会那么快过时。
用户输入不可信。
外部调用会失败。
数据口径会漂。
权限要收紧。
日志要能查。
成本要能归因。
测试要能回归。
发布要能灰度。
变更要能回滚。
高风险节点要有人确认。
这些东西,放在传统后端系统里成立。
放在 AI 应用里也成立。
只是 AI 应用让它们更难,也更重要。
所以,开发者转向 AI 应用工程,不要先否定自己过去的积累。
你真正要做的,是把已有的工程判断力迁移过来:
从接口迁移到模型调用。
从数据链路迁移到 RAG。
从工作流迁移到 Agent。
从配置和文档迁移到 Context Engineering。
从测试回归迁移到 AI Evaluation。
从 API Gateway 迁移到 LLM Gateway。
从研发流程迁移到 AI Coding Workflow。
这就是我看 AIGuide 这条路线时,最想留下的一句话:
AI 应用开发不是让开发者变成另一个物种,而是让开发者重新理解自己已经掌握的工程能力。
来源说明
本文内容主要基于 Snailclimb / JavaGuide 体系下的开源项目 AIGuide 整理,并结合我自己的阅读理解做了重写和串联。原项目与在线阅读地址如下:
- • https://github.com/Snailclimb/AIGuide
- • https://javaguide.cn/ai/
- • https://javaguide.cn/ai-coding/
往期推荐:学 AI 应用开发,别只背概念LLM API 不是聊天接口,而是一条工程调用链RAG 最难的不是向量库,而是知识链路Agent 不是会调工具,而是能推进任务Prompt Engineering 之后,真正要学的是 Context Engineering评测不是打分,而是 AI 应用的回归系统大模型网关,才是 AI 应用进入生产的分水岭AI Coding 不是让 AI 写代码,而是重组研发流程Spec、Skill、Agent,怎么组成一条可控的软件生产线
登录查看剩余 70% 内容
-
07.24
吉星派对阿兰娜玩法攻略
-
07.24
iPhone17Pro系列有啥颜色
-
07.24
奥特曼超时空英雄战斗技巧有哪些
-
07.24
魔域中何为东方美
-
07.24
原神月之三角色卡池如何选择
-
07.24
我的冬季汽车官网地址在哪
-
专题
三国战纪-风云再起 整合版
-
专题
三国战纪-乱世枭雄
-
-
- 飞凌嵌入式现身慕尼黑上海电子展
- 07.04
-
-
-
-
- AI越强:测试越重要
- 07.04
-
-
下载
- |
-
-
下载
- 《行尸走肉第一章》免安装中文汉化硬盘版下载
- 单机|436 MB
- 一款以动作冒险为主题的游戏
-
-
下载
- 《街头霸王X铁拳》免安装中文汉化硬盘版下载
- 单机|111MB
- 一款非常好玩的格斗游戏
-
-
下载
- |
-
-
下载
- 《暗黑破坏神3》免安装繁体中文正式版下载
- 单机|7630 MB
- 一款以角色扮演为主题的游戏
-
-
下载
- 《马克思佩恩3》免安装硬盘版下载
- 单机|27033 MB
- 一款以第三人称射击为主题的游戏