刚刚:美团 LongCat-2.0 发布并开源:五万卡国产算力跑出万亿参数 Agent 模型 | BestBlog...
原创 NLPer 2026-06-30 16:49 江苏
美团龙猫团队发布 LongCat-2.0
今天,美团龙猫团队发布 LongCat-2.0,并将对外开源。这是一个面向智能体式编程(Agentic Coding)和长程任务的大规模 MoE 语言模型:总参数 1.6T,平均每个 token 激活约 48B,原生支持 1M 上下文,完整训练和部署跑在 AI ASIC superpods 上。
LongCat-2.0 的定位很明确:给 Claude Code、OpenClaw、Hermes 这类 harness 提供可接入的底层模型,用来处理代码理解、仓库级改写、自动任务执行和多步骤工作流。LongCat API 文档也已经列出 OpenAI API 格式、Anthropic API 格式,以及 Claude Code、Kilo Code、OpenCode、OpenClaw、Codex 等编程工具的接入方式。
简单说,LongCat-2.0 是美团把万亿参数 MoE、1M 长上下文、国产算力训练和代码智能体接入放到一起的一次发布。模型本身负责代码理解、仓库级编辑和长程任务执行,背后还有训练、推理、API 兼容和工具接入这一整套工程链路。它的重心已经从聊天扩展到代码智能体,更接近一个为复杂开发任务准备的底座模型。
国产算力上的训练闭环
LongCat 团队从 2023 年开始探索国产算力。按照龙猫团队给出的路线,他们从千卡规模起步,逐步解决算子适配、通信优化、分布式稳定性等问题,最后在五万卡国产算力集群上完成 LongCat-2.0 的训练与推理。
LongCat-2.0 的训练和部署基于大规模 AI ASIC superpods。相比成熟的 NVIDIA GPU 生态,替代硬件平台的软件栈、调试工具和社区经验都更薄,模型团队需要把训练稳定性、数值正确性、并行策略和故障恢复一起补上。
| 工程问题 | LongCat-2.0 的处理方式 |
|---|---|
| 训练可复现 | 通信和计算路径都加强确定性,Embedding、FA、LSA、MoE 等模块使用自研确定性算子 |
| 数值可靠性 | Reduce 类算子采用分段二叉树累加,降低浮点误差累积,并在关键算子中加入 bit-flip 检测 |
| 大规模并行 | 在 TP、CP、EP、DP、PP 之外,引入 EMBP 来并行 N-gram Embedding |
| 内存压力 | 使用 ZeRO-1、选择性重计算、OOM-aware offloading,并把 padding token 路由到 zero-expert |
| 长上下文训练 | 使用 all-gather-based CP 并行方案,CP 可以扩展到 512 以上,支撑原生 1M 长度训练 |
| 吞吐优化 | 流水线调度、显存优化和算子级控核带来训练 MFU 约 1.5 倍提升 |
美团龙猫团队把一个万亿参数 MoE 模型从训练、长上下文、推理部署到 API 服务的链路跑通了,而且这条链路建立在国产算力集群上。
为 Agentic Coding 做的模型结构
LongCat-2.0 的架构围绕三个关键词展开:长上下文、动态计算、多专家融合。
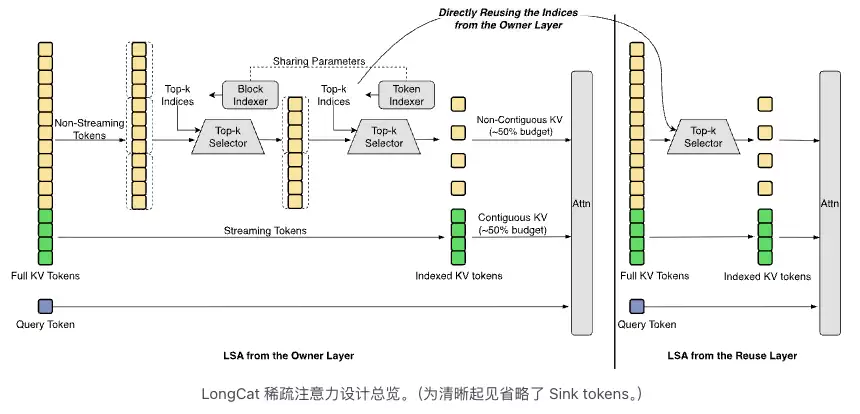
第一是 LongCat Sparse Attention(LSA)。它是对 DeepSeek Sparse Attention 的演进,目标是降低长上下文处理里的 indexer 开销。LSA 里有三个组件:Streaming-aware Indexing、Cross-Layer Indexing 和 Hierarchical Indexing,分别处理连续访存、跨层复用和粗到细候选筛选。对于 Agent 任务来说,1M 上下文真正有用的地方,在于能把代码库、文档、日志、历史交互一起放进同一轮任务里。
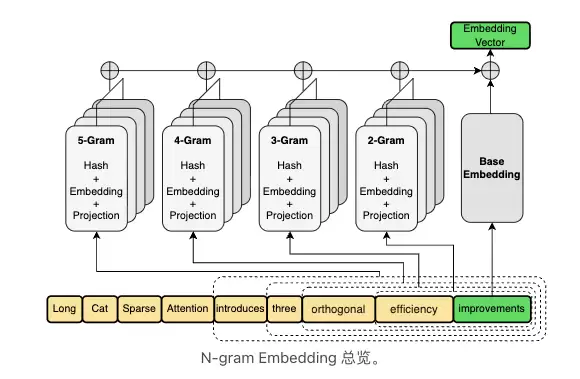
第二是 N-gram Embedding。LongCat-2.0 从 LongCat-Flash-Lite 继承了这个模块,并在模型里放入 135B N-gram Embedding 参数。它的思路是把参数扩展到 MoE 之外的稀疏维度,通过 N-gram token 组合捕捉更丰富的局部上下文。LongCat-2.0 的 MoE 稀疏率已经接近 97%,继续堆专家的边际收益有限,把一部分参数预算放到 N-gram Embedding 上更有意义。
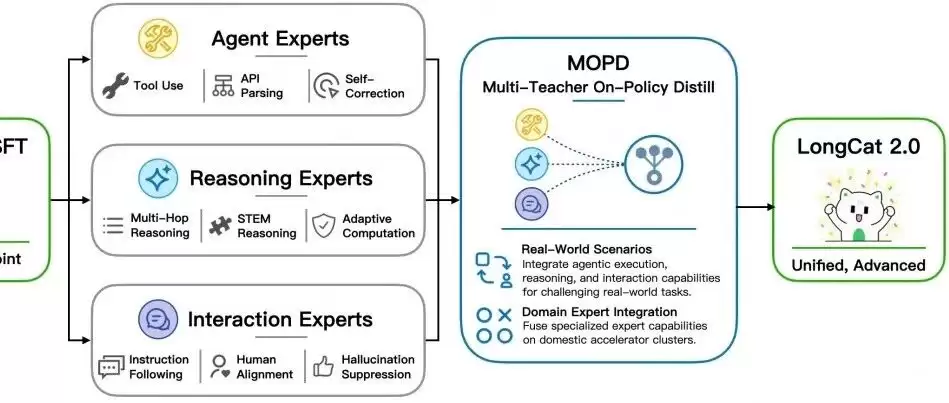
第三是 MOPD 多专家融合。后训练阶段被拆成三类专家:Agent Experts 处理工具调用、API 参数解析和自我纠错;Reasoning Experts 强化数学、STEM 和多跳推理;Interaction Experts 负责指令跟随、对齐体验和幻觉抑制。最后再通过 MOPD 把这些能力融合到一个模型里。
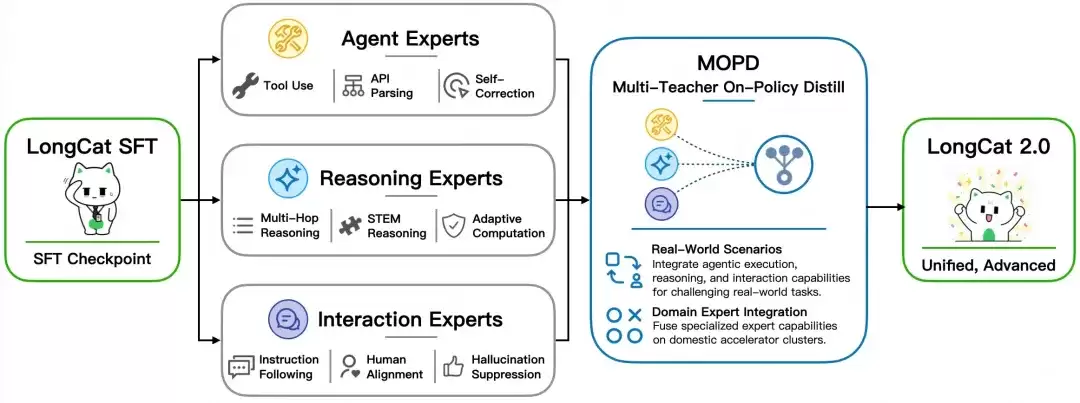
这也是 LongCat-2.0 为什么反复强调 Agentic Coding 的原因。真实的代码智能体任务很少只考一道算法题,它通常要读完整仓库、理解迁移文档、调用工具、运行命令、看报错、再修复。模型要同时有长上下文、工具调用、推理、交互和自我纠错能力。
评测结果
LongCat-2.0 的评测集中放在 Code Agent 和 General Agent 场景下,图表里包含 Gemini 3.1 Pro、GPT-5.5 以及 Claude Opus 4.6/4.7/4.8 等闭源模型。图表口径里,带星号的是外部报告指标,其余成绩为 LongCat 团队在统一 harness 下测得。
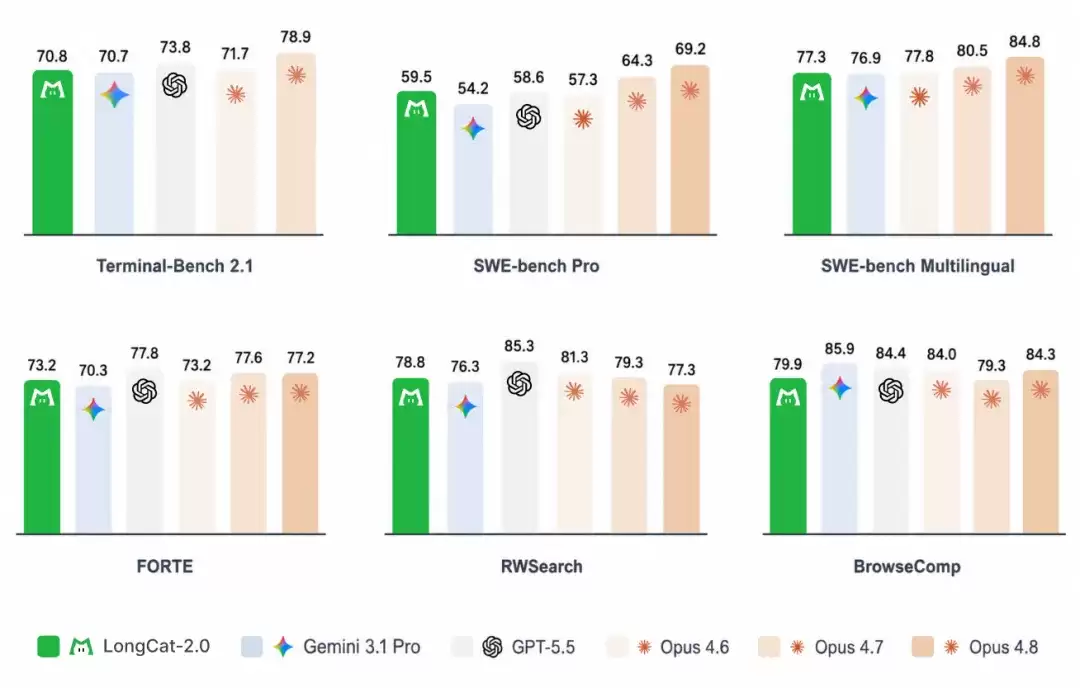
从图表看,LongCat-2.0 在 Terminal-Bench 2.1 上是 70.8,和 Gemini 3.1 Pro 的 70.7 基本持平;在 SWE-bench Pro 上是 59.5,高于 Gemini 3.1 Pro、GPT-5.5 和 Claude Opus 4.6 图表成绩,但低于 Claude Opus 4.7/4.8。SWE-bench Multilingual 图表给出 77.3,接近 Claude Opus 4.6 的 77.8。
到了通用 Agent 和搜索场景,LongCat-2.0 在 FORTE 上是 73.2,在 RWSearch 上是 78.8,在 BrowseComp 上是 79.9。这些分数不能简单读成“谁全面领先”,因为不同 benchmark 的任务、工具、超时限制、采样参数和是否采用外部报告值都不一样;更合理的读法是,LongCat-2.0 已经把能力重点压到真实工具环境和长程任务上,评测重心也从聊天和单轮问答转向了更复杂的任务执行。
实际演示
LongCat-2.0 的官方给了 5 个演示视频,覆盖数据分析、代码迁移、应用开发、3D 交互和内容生产几类场景。按视频顺序看,核心是模型能不能把一个相对完整的工作任务推进下去。
第一类是 AI SQL Agent。业务人员用自然语言提出数据问题,LongCat-2.0 需要理解问题意图、规划查询步骤、生成 SQL,并把查询结果整理成业务可读的解释。这类任务考验的是一整条链路:意图理解、查询规划、结果解释和工具闭环,每一步都要稳定接上。
第二类是代码库迁移。给模型一个旧版插件代码库和一份新版 SDK 文档,它需要先理解项目结构,再把插件迁移到新的接口模式,并保留原有功能。这个例子比单文件改代码更接近真实开发,因为模型要同时处理旧代码、目标接口、潜在兼容问题和最终可运行结果。
第三类是完整应用开发。用户只描述一个“儿童 AI 游戏训练场”的想法,LongCat-2.0 要继续补齐技术选型、页面结构、游戏逻辑和视觉细节,最后生成多个可玩的页面。这个样例主要看模型有没有长程规划和工程组织能力,已经超出一段局部代码生成。
第四类是 Three.js 3D 交互演示。用户一句话描述透明烧瓶、荧光液体、泡沫喷发、液面下降和堆积效果,模型生成一个可以直接打开的 HTML 文件。这个例子把代码生成、视觉状态和交互效果放在一起,能更直观看出模型对前端运行结果的组织能力。
第五类是 AI 小说工厂。这个样例把创意写作拆成世界观构建、章节生成、质量评估、回流修订和多平台发布等步骤,再用长上下文维持设定一致性。它更像一个多 Agent 内容流水线,已经超出简单续写几段文字的范畴。
这些例子都指向同一件事:LongCat-2.0 想进入的是“代码智能体作为工作执行器”的场景。模型输出要从回答继续向前走,读材料、写代码、调用工具、解释结果,并把任务推进到可交付状态。
总结
LongCat-2.0 这次发布的核心看点落在三件事上:模型规模、算力闭环和 Agent 工作流。1.6T 总参数、平均激活约 48B、原生 1M 上下文,把模型容量和上下文窗口拉到了高位;五万卡级 AI ASIC superpods,把国产算力上的训练、长上下文并行、推理服务和稳定性工程串成了一条链;Agentic Coding,则把模型能力直接指向代码仓库、工具调用、长任务执行和真实工作流。
之后的检验会更具体,它能不能稳定读完整仓库、理解迁移文档、改代码、跑工具、看报错、再修复;能不能在数据分析 Agent、代码迁移、应用生成和企业内部长任务里保持可控;等权重、部署文档和更多真实项目实测出来之后,答案会逐渐清楚。LongCat-2.0 给出的信号很明确:国产大模型已经开始正面进入代码智能体这一轮工程竞争。
参考链接
-
LongCat-2.0 介绍页:https://longcat.chat/blog/longcat-2.0
-
LongCat-2.0 GitHub 仓库:https://github.com/meituan-longcat/LongCat-2.0
-
LongCat-2.0 Hugging Face 模型页:https://huggingface.co/meituan-longcat/LongCat-2.0
-
LongCat API 中文文档:https://longcat.chat/platform/docs/zh/
-
LongCat Chat:https://longcat.ai/
-
LongCat API 平台:https://longcat.chat/platform/
进技术交流群请添加AINLP小助手微信(id: ainlp2)
请备注具体方向+所用到的相关技术点

关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括LLM、预训练模型、自动生成、文本摘要、智能问答、聊天机器人、机器翻译、知识图谱、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

-
07.26
洛克王国世界测试服下载去哪 洛克王国世界测试服怎么进
-
07.26
我的世界森罗物语模组常用工具合成配方
-
07.26
球比伦战记下载地址 球比伦战记下载教程
-
07.26
花之舞沉睡魔咒活动守护通关方法教程(持续更新)
-
07.26
幻想生活i能够获取配方的红宝箱获取位置点
-
07.26
恶魔秘境流浪旅人冒险怎么打
-
专题
三国战纪-风云再起 整合版
-
专题
三国战纪-乱世枭雄
-
-
下载
- |
-
-
下载
- 《行尸走肉第一章》免安装中文汉化硬盘版下载
- 单机|436 MB
- 一款以动作冒险为主题的游戏
-
-
下载
- 《街头霸王X铁拳》免安装中文汉化硬盘版下载
- 单机|111MB
- 一款非常好玩的格斗游戏
-
-
下载
- |
-
-
下载
- 《暗黑破坏神3》免安装繁体中文正式版下载
- 单机|7630 MB
- 一款以角色扮演为主题的游戏
-
-
下载
- 《马克思佩恩3》免安装硬盘版下载
- 单机|27033 MB
- 一款以第三人称射击为主题的游戏