跨平台多模态智能体基准测试来了:但全班第一只考了35.26分
基于Crab框架,作者开发了一个基准测试Crab Benchmark-v0,支持Android环境和Ubuntu环境。
基准测试总共包含100个真实世界的任务,包括跨平台和单平台跨多个难度级别的任务。
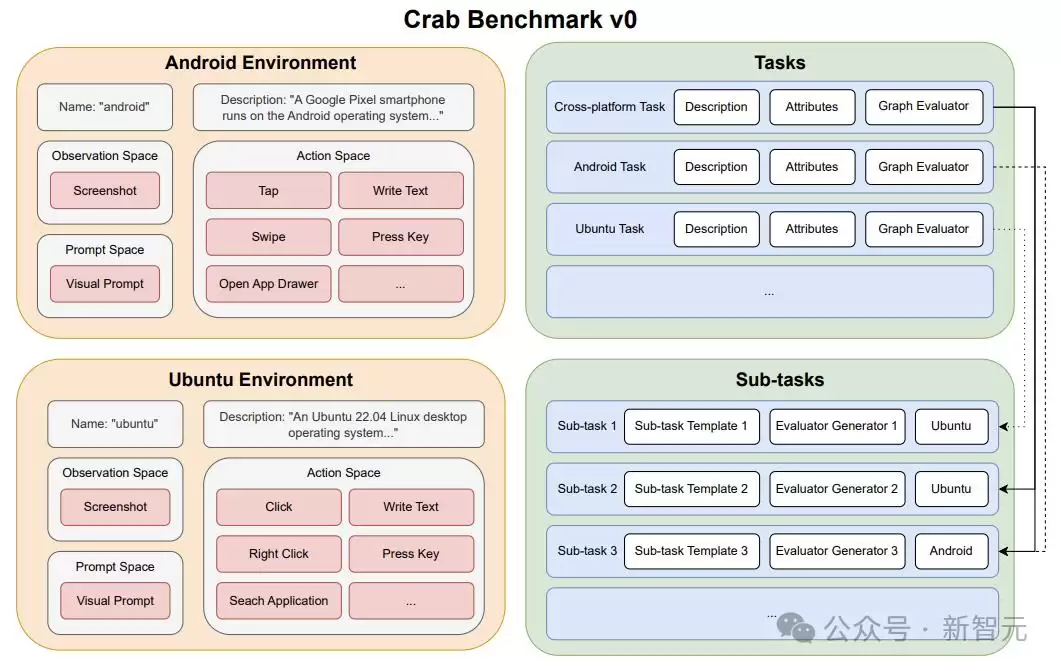
任务涉及各种常见问题,以及实际应用程序和工具,包括但不限于日历、电子邮件、地图、网络浏览器、和终端,以及智能手机和台式机之间的常见交互。
框架
假设Agent在数字设备(比如台式机)上自主执行任务。这种设备通常有输入设备(鼠标和键盘)用于人机交互,以及输出设备(屏幕)来允许人类观察其状态。
作者将这种类型的设备表示为一个平台。在形式上可以定义为一个无奖励的部分可观测马尔可夫决策过程(POMDP),用元组M:=(S,A,T,O)表示。
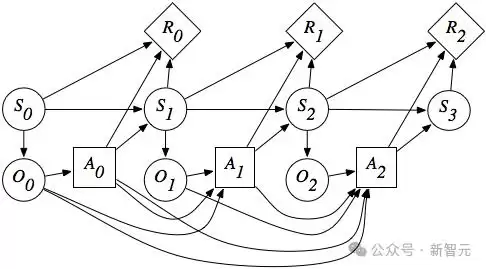
其中S表示状态空间,A表示动作空间,T:S×A→S是转移函数,O是观测空间。
考虑到现实场景中多个设备的协作性质,可以将多个平台组合成一个集合M=M1,M2,…,Mn,其中n是平台的数量,每个平台Mj=(Sj,Aj,Tj,Oj)。
定义一个需要跨多个平台操作的任务,该任务被形式化为一个元组(M,I,R),其中M是平台集合,I是以自然语言指令的形式表示的任务目标,R是任务的奖励函数。
系统中的Agent使用预定义的系统提示、并保留其对话历史记录。
Agent系统由负责规划、推理和执行操作的单个Agent组成,或者由多个Agent进行协作。
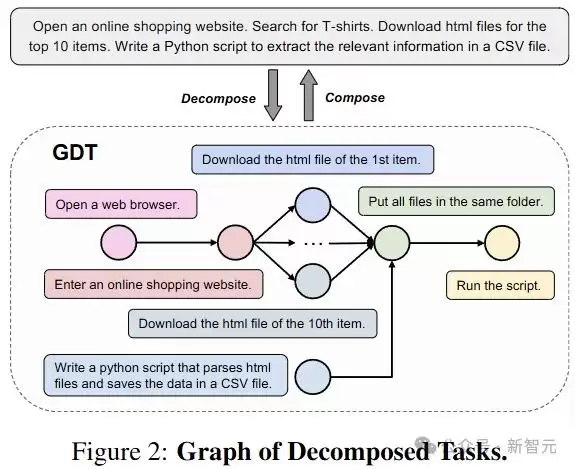
把复杂任务分解为多个更简单的子任务,是让Agent系统能够更加精准的完成复杂任务的方法之一。
研究人员将这一概念引入基准测试领域,将复杂任务分解为具有顺序和并行连接的子任务,也就是上图中的分解任务图(GDT)。
GDT提供了一种新的任务分解方法:用DAG结构表示分解后的子任务。在GDT中,每个节点都是一个子任务,形式化为一个元组(m,i,r),其中m指定了执行子任务的平台,i提供了自然语言指令,r表示奖励函数。
这个函数评估m的状态并输出一个布尔值,以确定子任务是否完成。GDT中的边表示子任务之间的顺序关系。
跨平台
与单一平台任务相比,跨平台任务有三个主要优势:
首先,跨平台任务反映了现实世界场景,人类同时使用多个设备来完成任务。
其次,这些任务需要在平台之间进行复杂的消息处理和信息传递,要求Agent规划行动、为每个平台构建输出,并记住需要传递的内容,从而展示出对现实世界的高层次理解,和解决复杂任务的能力。
最后,多Agent系统被证明在执行复杂任务时更加有效,而跨平台任务非常适合多Agent系统,因为它们可以通过每个平台中不同的观测空间、行动空间和专门知识进行划分。
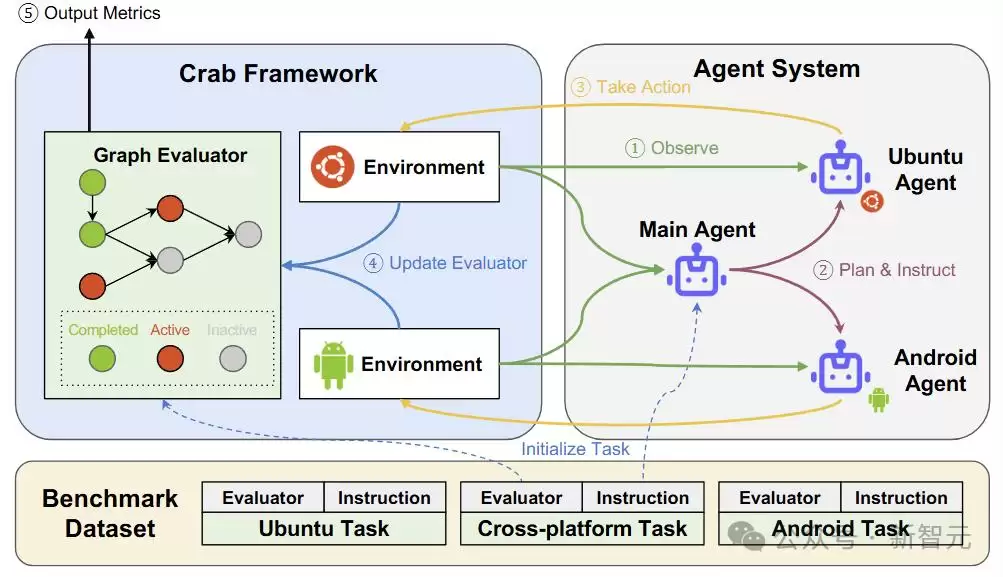
Crab使用统一接口允许Agent在所有平台中操作。作者通过名称、所属平台、功能的具体描述和参数来定义一个动作。
Agent必须在每个回合提供动作名称、参数和目标平台。Crab将动作转换为相应的功能,并通过网络将其路由到物理或虚拟设备。
图评估器
为了评估大语言模型作为Agent的能力,大多数基准测试仅基于Agent操作后平台的最终状态来评估Agent。
只判断最终目标是成功还是失败,显然不够公平,就像大题不会做,但写个解是应该给分的。
另一种方法是基于轨迹匹配,将Agent的操作与每个任务的预定义标准操作序列进行比较。
然而,在现实世界系统中,任务可能有多条有效的执行路径,比如复制文件可以使用文件管理器,也可以使用命令行。
评估指标
所以本文采用了与平台状态同步的图评估器,通过子任务完成的当前状态来跟踪Agent的进度。
除了传统的成功率(SR),只有在所有子任务都完成时才将任务标记为成功,作者还引入了三个指标,衡量Agent的性能和效率:
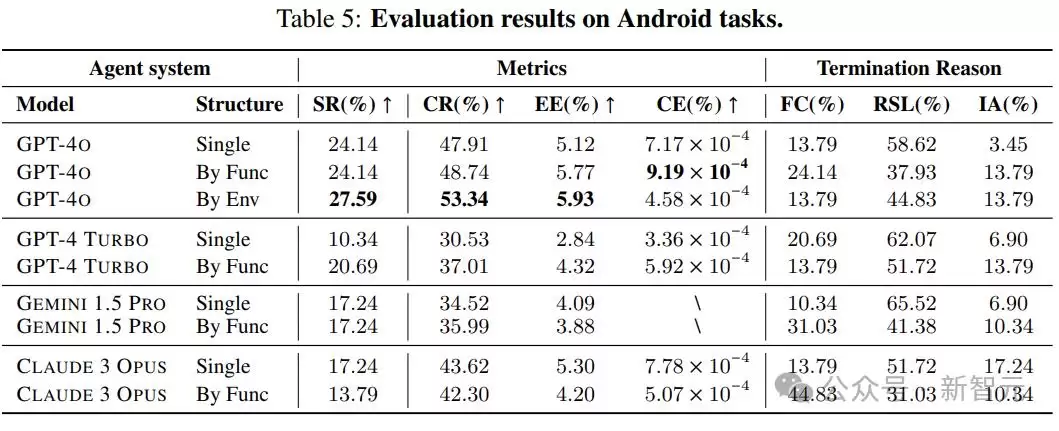
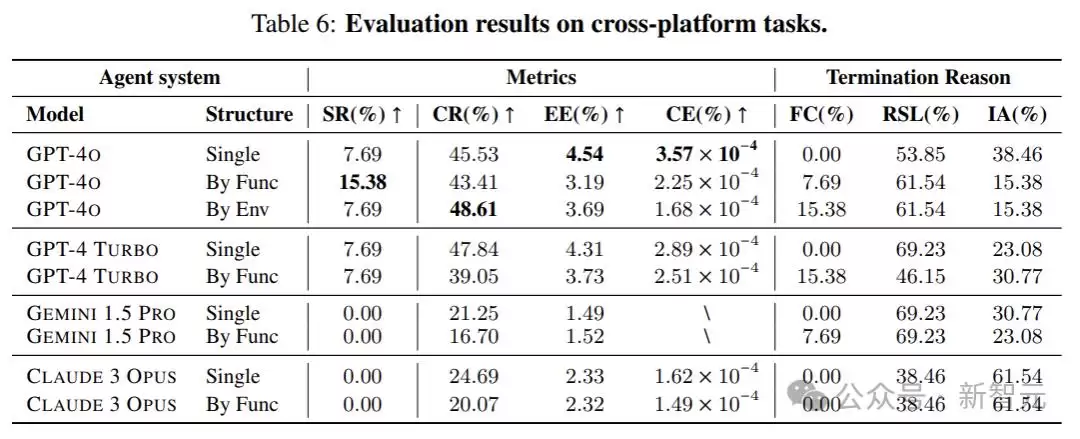
实验选择了四种满足这些标准的多模态模型:GPT-4o、GPT-4 Turbo、Gemini 1.5 Pro和Claude 3 Opus,下表给出了其中一部分结果:
参考资料:
https://github.com/camel-ai/crab
https://arxiv.org/abs/2407.01511
https://github.com/camel-ai
-
07.28
猎人启程手游如何玩
-
07.28
云崩坏星穹铁道免费游戏秒玩入口 云崩坏星穹铁道网页版在线直接畅玩
-
07.28
天涯明月刀手游怎么获得神品心法残页_天刀心法升级材料操作
-
07.28
我的世界基岩版如何获得屏障方块 屏障指令获取方法
-
07.28
死亡教堂15天通关完美路线:如何平衡腐败度与战力提升
-
07.28
《境·界刀鸣》魂玉获取方法_《刀鸣》角色养成核心货币用途教程
-
专题
三国战纪-风云再起 整合版
-
专题
三国战纪-乱世枭雄
-
-
下载
- |
-
-
下载
- 《行尸走肉第一章》免安装中文汉化硬盘版下载
- 单机|436 MB
- 一款以动作冒险为主题的游戏
-
-
下载
- 《街头霸王X铁拳》免安装中文汉化硬盘版下载
- 单机|111MB
- 一款非常好玩的格斗游戏
-
-
下载
- |
-
-
下载
- 《暗黑破坏神3》免安装繁体中文正式版下载
- 单机|7630 MB
- 一款以角色扮演为主题的游戏
-
-
下载
- 《马克思佩恩3》免安装硬盘版下载
- 单机|27033 MB
- 一款以第三人称射击为主题的游戏