Loop Engineering - Agent真正智能的来源
> Loop 工程:驱动整台机器持续运转的外环
---
引言:同样接了大模型,凭什么有的叫 Agent,有的只是 chatbot?
这是一个被问烂、却很少有人答到点子上的问题:大模型本身,算 Agent 吗?你公司接入的那个模型,做出来的到底是个 chatbot,还是个 Agent?
凭直觉,大家都能感觉到两者不一样:一个是你问一句它答一句,问完就结束;另一个会自己盯着一个目标,调工具、查资料、出错了重来,一步步把事情做完。
这个差别的根源,不在模型有多强,而在一个常被忽略的东西——**Loop(循环)**。
本系列前几篇,我们一层层往外走:Prompt 决定模型怎么思考,Context 决定它基于什么思考,Harness 让模型之外的执行变得可靠。但这三层加起来,还只是一堆静态的、强大的零件。**是谁在驱动这些零件,让它们持续运转、自我推进、直到把任务真正做完?是最外面那一环——Loop。**
这一篇,我们就来讲这个最外环。但开篇我得先把那句流行的话——"没有 loop,就没有 agent,只有 chatbot"——说得更准确一点。因为它很抓人,却也略过头了。
---
一、先把那句流行的话说准确
"没有 loop,就没有 agent,只有 chatbot。"这句话很 punchy,适合做标题。但作为一个严谨的工程判断,它需要一个诚实的限定。
严格来说,**一次带工具调用的单轮交互,在宽松的定义下,也勉强算个 agent**——它毕竟也"自主"地选了个工具、采取了行动。所以 loop 并不是"是不是 agent"的开关。
更准确的表述是:
> **Loop 决定的不是"是不是 agent",而是 agent 的鲁棒性和自主性——它能不能在一个不确定的环境里,持续、可靠地把任务做完。**
这正好接上本系列第一篇给 agent 下的定义:Agent = 能在不确定环境中**持续完成**任务的**闭环**系统。注意"持续"和"闭环"这两个词——它们指向的,就是 loop。
把 chatbot 和 agent 摆在一起,差别一目了然:
- **chatbot**:一问一答,单向推进,无状态。它不会因为答得不好就自己重来,也不会盯着一个大目标分多步去完成。
- **agent**:在一个闭环里运转,盯着目标,观察、判断、行动、校验,出错了就调整,做完了才停。它有状态,会自我推进。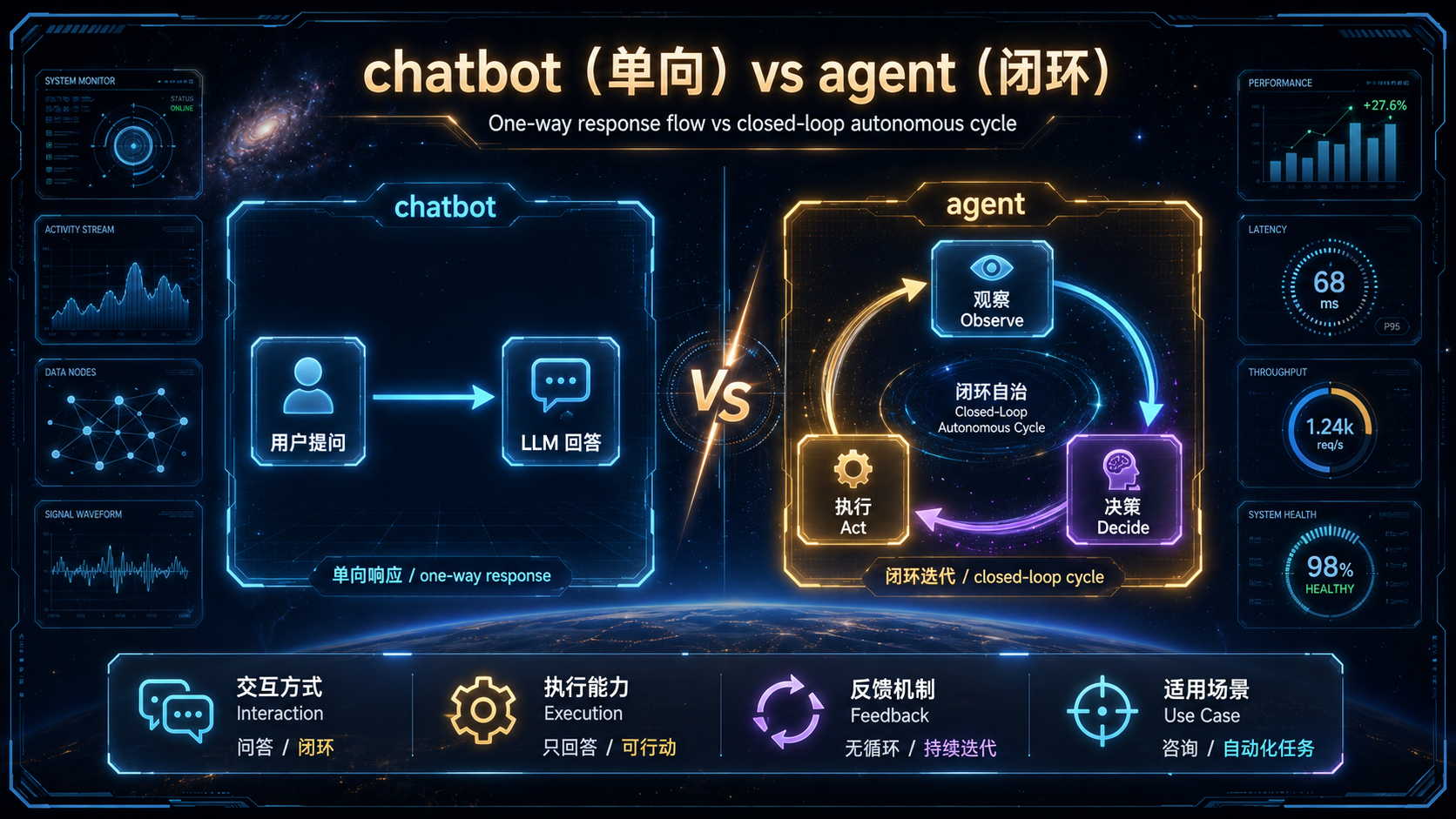
为什么 loop 是"智能"的来源?这里有一个关键的洞察:**单次调用的智能,是固定的;而 loop 让系统能通过"多步 反馈 修正",把这份固定的单步智能,复利成完成复杂任务的能力。**
一个模型一次能做的判断有限,但把它放进一个会循环、会根据结果调整的闭环里,它就能逐步逼近一个单次调用永远够不着的复杂目标。这就像复利——单期收益不高,但持续复利之后,威力惊人。**Agent 真正的"智能",不在那一次更聪明的调用里,而在这个把简单智能复利起来的循环里。**
拿招投标再具体一下这个"复利"。如果你只调一次模型——"读完这份招标文件,告诉我该不该投、报多少"——它给你的,是一次性的、信息过载下的粗判断,大概率不靠谱。但如果把它放进闭环:第一轮只判断"硬性资质是否满足",第二轮基于这个结论再去比对历史中标价,第三轮结合前两轮再测算报价与风险……每一轮都站在前一轮的结论之上,单步的判断不难,但一圈圈叠下来,就逼近了一个单次调用永远给不出的严谨结论。**chatbot 拿到的是"一次性的回答",agent 拿到的是"层层逼近的结论"——这,就是 loop 带来的质变。**
---
二、Loop 的本质:一个由代码掌控的控制流,不是让模型自由循环
理解了 loop 的价值,紧接着是最容易踩坑的地方。很多人一听"让 Agent 自己循环",就真的放手让大模型漫无目的地自我循环——想停就停、想继续就继续,全凭模型自觉。
**这是个灾难性的误解。**它正是无数 Agent 不可靠、烧钱、失控的根源。
想象一个被"放任自循环"的招投标 Agent:它读了一段条款,觉得"信息还不够,再查查吧",于是又调了一次检索;结果还是觉得不够确定,再查、再想、再查……没有人告诉它"够了,该下结论了"。它就这样在一个判断上反复横跳,转了二十几轮,烧掉一大笔 token,最后要么超时崩溃,要么给出一个和第三轮时差不多的结论。**它不是不聪明,它是没人握方向盘。**这种"模型自己决定要不要继续"的设计,在 demo 里因为任务短、跑得顺,看不出问题;一到真实的复杂任务上,立刻原形毕露。
正确的认知是(这也呼应了前面几篇反复强调的):
> **Loop 不是让 LLM 自由循环,而是一个显式的、由你的代码掌控的控制流。**
「12-Factor Agents」里有一条核心原则叫"掌控你自己的控制流":循环、终止、状态更新这些骨架,应该写在你的代码里——跑一个显式的 OODA 式闭环、带明确的收敛启发式,而不是把控制流嵌套进 prompt 里、求模型自觉。
具体到每一轮,loop 做的事其实很清晰:**LLM 负责"思考下一步该做什么",并输出一个结构化的指令(比如一个 tool call);然后由你的代码去执行它,把结果喂回去;接着进入下一轮的思考。**
这里的分工是决定成败的关键:
- **模型负责的**:在每一步,判断"下一步该做什么"。
- **工程负责的**:什么时候停、要不要重试、状态怎么更新、循环不能超过几轮。把"何时停、是否继续"这种控制权交给模型,等于把方向盘交给一个会走神的司机。Loop 工程的核心,就是把这个方向盘牢牢握在代码手里——**让模型决定"走哪一步",但由工程决定"整段路怎么走、什么时候到站"。**---## 三、三种经典 Loop:从 ReAct 到 Plan-Execute业界对 loop 的设计,演化出了几种经典范式。理解它们,是设计自己 loop 的基础。**第一种,ReAct loop(Reasoning Acting)。**这是最基础、也最有名的一种,由 Yao 等人在 2023 年提出。它的节奏是:**思考(Think)→ 行动(Act)→ 观察(Observe)**,然后循环。模型先想"我该干什么",做一个动作(调工具),看返回结果,再基于结果想下一步。它边想边做边看,特别适合那种**路径不确定、需要探索**的任务。局限是:如果缺乏全局规划,它可能在中途"走偏",绕了很多无用的弯。**第二种,Plan-Execute loop(先规划再执行)。**它的节奏是:**规划(Plan)→ 执行(Execute)→ 校验(Verify)**。模型先把整个任务拆成一个计划,再逐步执行,最后校验。相比 ReAct 的"走一步看一步",它多了一个全局视角,**适合步骤较明确、需要统筹规划**的任务,能减少中途乱走。代价是:计划一旦在执行中被证明不对,调整起来比 ReAct 更笨重。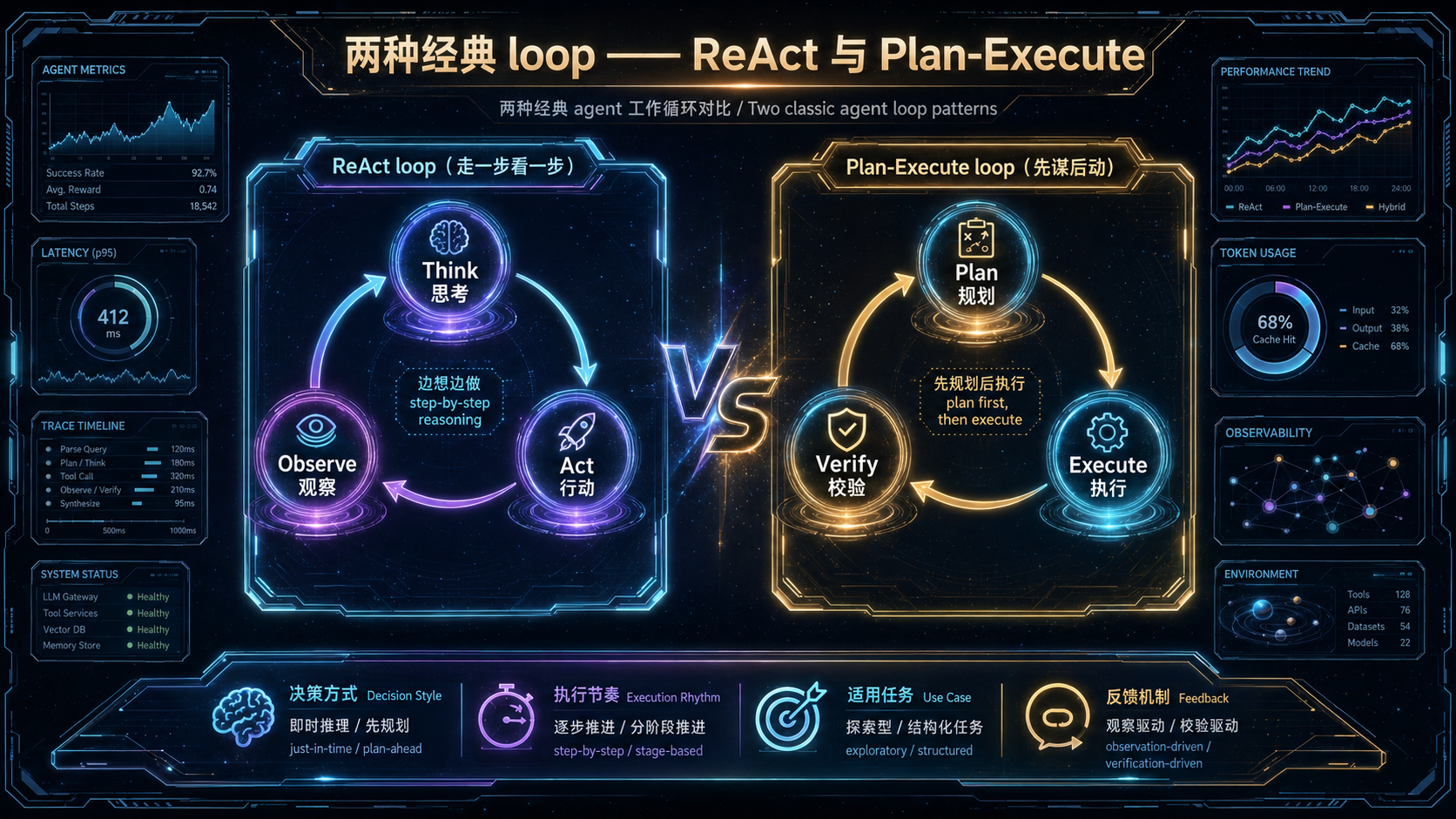
**还有一种值得一提,Reflexion 类的"反思"loop**:在行动之后,让系统对结果做一次反思,把"哪里做得不好"沉淀下来,用于改进下一次。它给 loop 加了一层自我批判的能力。
那企业到底该选哪种?给一个实用的选型判据:**任务的路径越不可预测,越偏 ReAct;任务的步骤越清晰、越需要全局统筹,越偏 Plan-Execute。**拿招投标举例——"逐条审查未知的招标条款"这种探索性强的环节,更适合 ReAct,走一步看一步;而"投标书的整体准备"这种步骤相对固定、需要统筹章节顺序的环节,更适合 Plan-Execute,先排好计划再逐项推进。现实中,一个成熟的企业 Agent 往往是**混合**的:在需要探索的子任务里用 ReAct,在需要规划的子任务里用 Plan-Execute,必要时再叠一层 Reflexion 做质量回看。别把"选哪种 loop"当成非此即彼的信仰之争,它只是按任务特性选工具。
这三种是通用的研究范式。但企业生产真正需要的,是把它们的精华揉进一个更完整、更可控的 loop。这才是重头戏。
---
四、企业级 Loop:把前面所有层串成一个持续运转的系统
前面几种 loop 偏研究范式,企业落地需要一种更完整的版本。它的节奏是六步:
> **检索(Retrieve)→ 决策(Decide)→ 执行(Execute)→ 校验(Validate)→ 更新状态(Update State)→ 重复(Repeat)**
这条 loop 最重要的地方在于,它不是凭空多出来的一种,而是**把本系列前几篇讲的所有层,串成了一个会持续运转的整体**。我们逐环对应:
- **Retrieve(检索)** —— 这就是 **Context 工程**:为当前这一步,喂对刚好够用的信息。
- **Decide(决策)** —— 这是 **LLM 在决策点**上做判断。- **Execute(执行)** —— 这是 **Harness** 调度工具去执行。
- **Validate(校验)** —— 这是 **Harness 的校验器**在拦幻觉、查约束。- **Update State(更新状态)** —— 这是 **loop 自己的核心职责**:把这一步的结果正确地写进状态,供下一轮使用。
- **Repeat(重复)** —— 在受控的预算和终止条件下,进入下一轮。看明白了吗?**外环"驱动"的含义,就在这里。**Loop 不生产智能、不执行工具、不组织信息——它做的是调度:决定此刻该检索什么、让谁判断、调哪个工具、何时校验、如何更新状态、要不要再来一轮。它是把 Prompt、Context、Harness 这些零件真正盘活成一台运转机器的传动轴。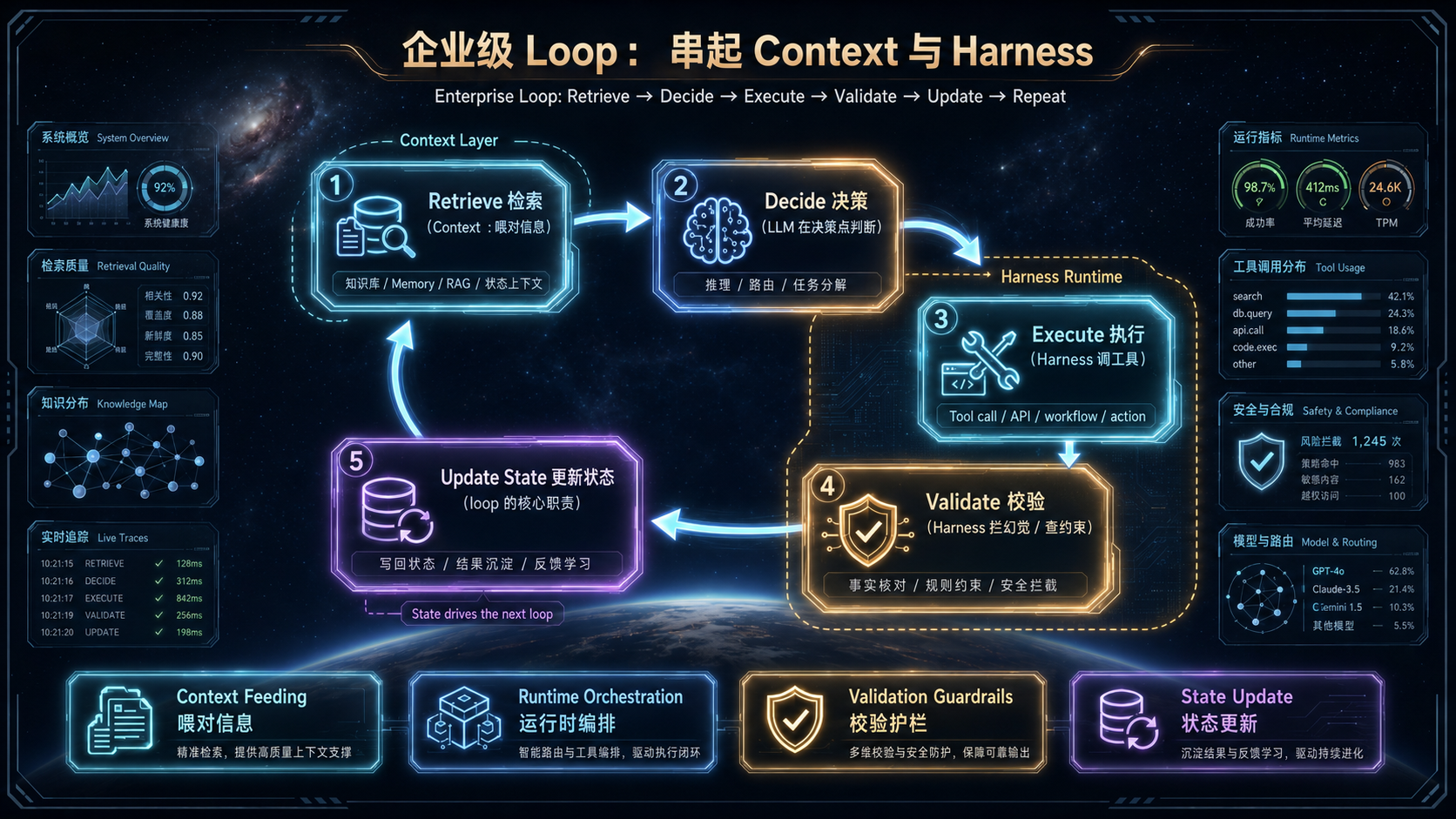
用招投标 Agent 走一遍这条 loop 就很具体了:检索本轮要判断的招标条款与相关历史(Retrieve)→ 判断这条是否构成废标风险(Decide)→ 调用条款库做精确比对(Execute)→ 校验比对结果与引用是否真实(Validate)→ 把"该条已确认/有风险"写进任务状态(Update State)→ 进入下一条款(Repeat),直到所有条款审完、报价与风险结论产出。**一圈圈转下来,一个模糊的"招投标分析",就被这条 loop 持续推进成了一份完整、可靠的结论。**
这里要特别点一下 **Update State** 这一环,因为它是 loop 独有、别人替不了的职责。Context 负责"喂什么"、Harness 负责"怎么执行",但"这一轮做完之后,整个任务的进度走到哪了、哪些条款已确认、哪些还悬而未决、下一轮该从哪接着干"——这份贯穿全程的任务状态,只有 loop 在维护。它就像项目经理手里那张不断更新的进度表:没有它,每一轮都像失忆一样从头开始,反复检索、反复确认、永远收敛不了。**状态的正确演进,是 loop 把一堆离散步骤黏合成一个连续任务的关键,也是它区别于"重复调用"的本质。**
---
五、企业落地的四个关键机制(一份 Loop 体检清单)
Loop 跑起来容易,跑得可靠难。让一条 loop 真正能上生产,有四个机制必须显式设计——这是你的 Loop 体检清单:
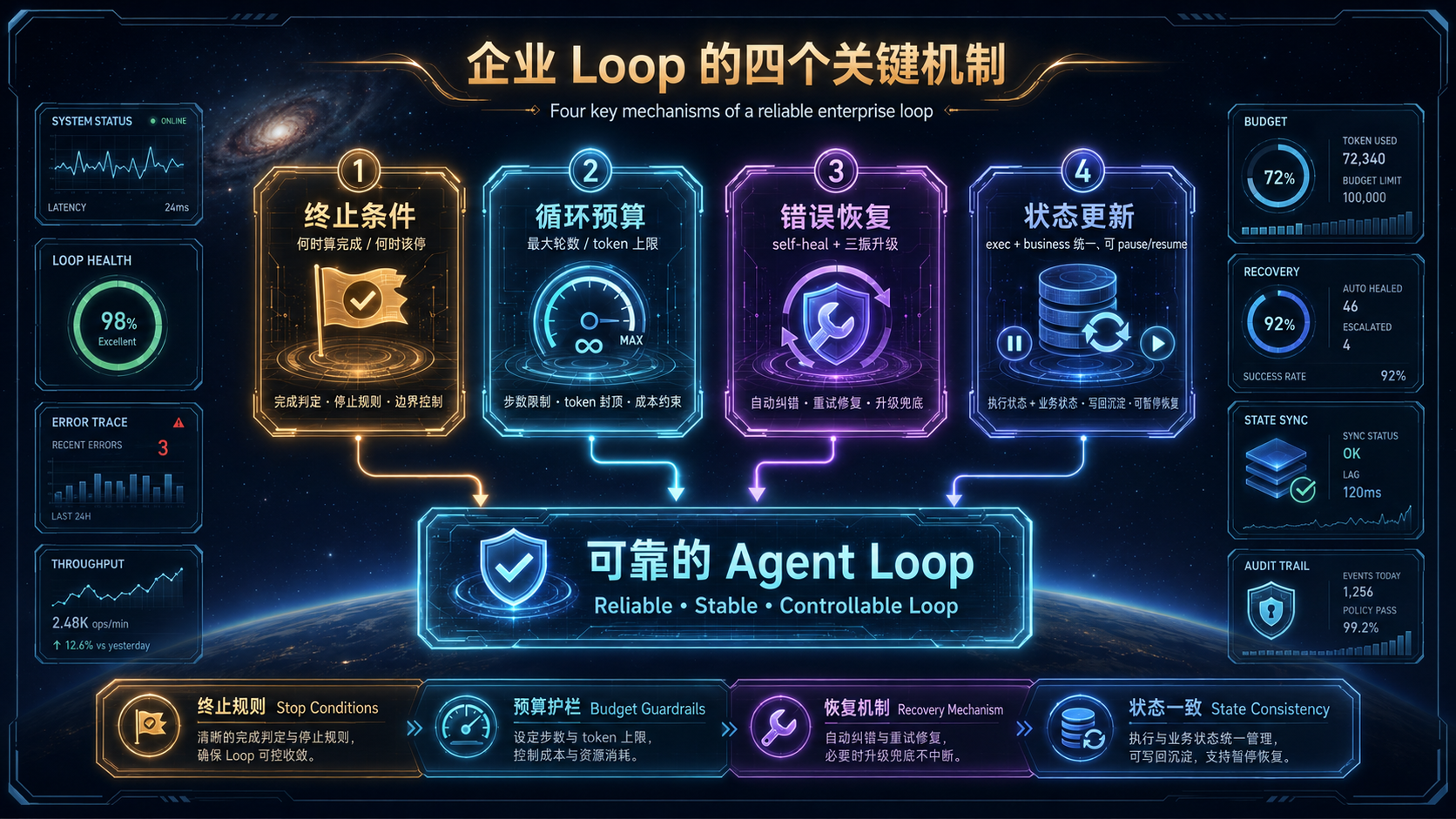- **① 终止条件(termination condition)**:什么情况算做完了?什么情况该停手?没有它,loop 要么永不停止,要么过早收尾。招投标的终止条件可以是"所有硬性条款已核对、报价与风险结论已产出并通过校验"。- **② 循环预算(loop budget)**:给每次任务设最大轮数、最大 token 上限。这是防成本失控的硬约束——上一篇提过,连 Anthropic 都坦言缺一个好用的"单次任务成本硬上限",所以预算闸必须自己建。
- **③ 错误恢复(error recovery)**:某一步失败时,把错误喂回上下文让模型自我修正(self-heal);但要设三振机制,连续失败就升级给人,绝不无限重试。- **④ 状态更新(state update)**:每一轮如何正确地演进状态?这里的关键工程实践是**把执行状态(execution state)和业务状态(business state)统一管理,并做到可暂停、可恢复(pause/resume)**——这样任务中断了能续上,重启了不会从头再来,也不会重复劳动。
把这四个机制合在一起看,招投标 Agent 的 loop 就有了完整的"安全带":它知道审完所有硬性条款且结论通过校验才算完成(终止条件),最多转 8 轮、超了就交人(预算),检索超时会重试两次、不行就升级(错误恢复),并且把"已审条款、待核疑点、当前报价草案"实时写进一份可续可恢复的状态表(状态更新)。少了任何一条,这条 loop 都会在某个深夜的真实流量里,以你意想不到的方式翻车。**这四个机制,不是锦上添花的优化项,而是 loop 能不能上生产的及格线。**
还有一条来自一线的反直觉经验,值得企业刻在心里:**带 error counter、会及时升级给人的小 loop,比塞了一堆复杂恢复逻辑的大 loop 更可靠。**别试图让一个庞大的 loop 用精巧的逻辑扛下一切——把它拆成职责单一的小循环,每个都做到 3–10 步的可靠区间,超过 20 步就拆(这正是第二、三篇讲过的复利衰减和拆子 loop)。**简单 早升级,几乎总是胜过复杂 强恢复。**
---
六、Loop 的反模式:让 demo 翻车的几种循环
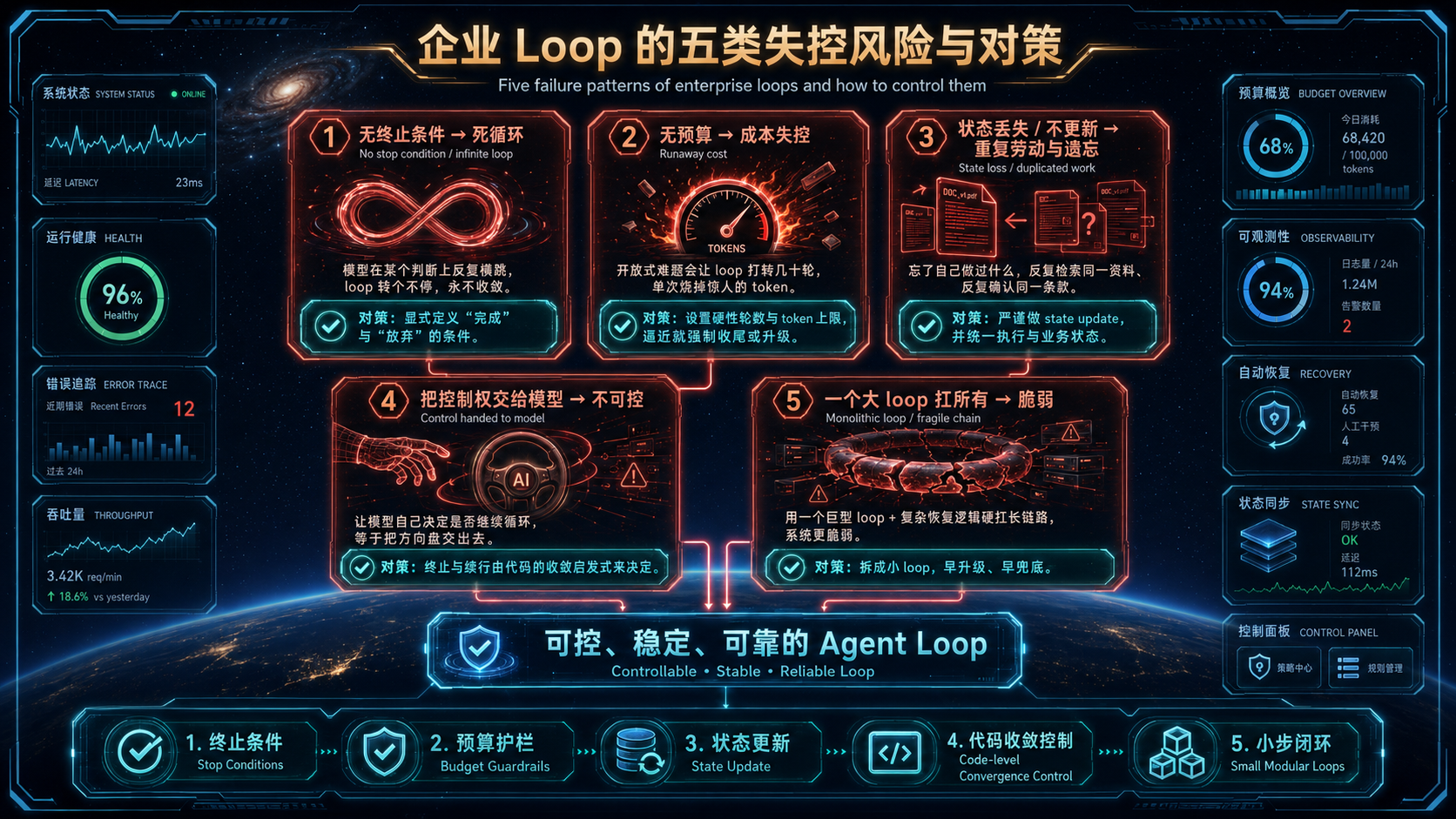把上面的机制反过来,就是几种最常见、最致命的 loop 反模式。出问题时,先按这份清单排查:
- **无终止条件 → 死循环。**模型在某个判断上反复横跳、永不收敛,loop 转个不停。**对策**:永远显式定义"完成"和"放弃"的条件。
- **无预算 → 成本失控(runaway cost)。**一个开放式难题,可能让 loop 打转几十轮、单次烧掉惊人的 token。**对策**:硬性的轮数与 token 上限,逼近就强制收尾或升级。- **状态丢失 / 不更新 → 重复劳动与遗忘。**每轮不正确地更新状态,模型就会忘了自己已经做过什么,反复检索同一份资料、反复确认同一个条款。**对策**:严谨的 state update,并统一执行与业务状态。
- **把控制权交给模型 → 不可控。**让模型自己决定"要不要再循环一次",等于放弃了方向盘。**对策**:终止与续行的决定,由代码的收敛启发式来做。- **一个大 loop 扛所有 → 脆弱。**用一个巨型 loop 复杂恢复逻辑硬扛长链路。**对策**:拆成小 loop,早升级、早兜底。
这五种反模式,几乎覆盖了生产里 loop 翻车的绝大多数情况。它们的共同点是:**都源于"放任循环"而非"掌控控制流"。**记住这条主线,排障就有了方向。
---
七、Loop 为什么是"智能"的来源——回到最外环
走到这里,我们可以回答开篇那个问题了:为什么有的是 chatbot,有的是 agent?
因为 chatbot 只有一次固定的智能,而 agent 有一个把固定智能**复利**起来的闭环。**Agent 真正的"智能",从来不是因为它的模型更聪明,而是因为它被一个会持续观察、判断、行动、校验、自我修正的 loop 驱动着,盯着目标不放,直到做完。**
把 Loop 放回那张同心圆:它是**最外环**,包在 Harness 之外,驱动着内部所有层——它消费 Context 组织好的信息、调度 Harness 执行的工具、决定整个系统的节奏与终点。它是让那台机器真正"动起来、转下去"的传动轴。
至此,四层 runtime——Prompt、Context、Harness、Loop——我们已经从内到外走完了一遍。一台能在不确定环境里持续、可靠地完成任务的 Agent 机器,结构上已经完整。
回望这趟由内而外的旅程,你会发现一条清晰的主线:每往外走一层,我们解决的就是上一层管不了的问题。Prompt 解决"怎么思考",但管不了"基于什么思考",于是有了 Context;Context 解决"喂什么",但管不了"模型之外怎么可靠执行",于是有了 Harness;Harness 给出可靠的执行积木,但管不了"什么时候调哪个、循环到何时停、状态怎么演进",于是有了 Loop。**四层环环相扣,缺一层,机器就转不起来——这正是第一篇那张同心圆想表达的:LLM 只是 CPU,外面这四圈 runtime,才共同构成一台能干活的机器。**而 Loop,是给这台机器点火、让它持续运转的那一环。
但是,**一个新问题浮现了:这台机器跑起来了,可它跑得对不对、好不好,你怎么知道?**
---
结论:给你的 Loop 做一次四要素体检
这篇文章想留给你的,是一把检查 loop 健康度的尺子:
> **拿出你的 Agent loop,问四个问题——有没有明确的终止条件?有没有循环预算?有没有错误恢复与升级?有没有严谨的状态更新?**
四个里缺任何一个,你的 loop 就埋着一颗在生产里随时会爆的雷。把本篇的核心判断收成一句话:
> **Loop 决定的是 agent 的鲁棒性与自主性(而非有无);它必须是一个由代码掌控的控制流,而不是放任模型自由循环;企业级 loop 把 Context 与 Harness 串成一个持续运转的系统,而智能,正来自这个闭环把简单智能复利起来的过程。**
如果你是技术决策者,现在就可以推动团队对现有 Agent 的 loop 做一次"四要素体检",并重点排查那五种反模式。这往往是把一个"偶尔失控的 demo"变成"稳定可控的系统"的关键一步。
最后,留一个问题,作为下一篇的引子:
我们已经把一台 Agent 机器从内到外搭完了。它能跑、能循环、能持续完成任务。可是——**你怎么知道它做得对?怎么知道这一版比上一版更好?当它在多 Agent 流水线里层层传递,错误会不会被悄悄放大?当你用一个模型去给另一个模型的输出打分,这个"裁判"本身公正吗?**
一个不能被可靠度量的系统,是无法被迭代、无法被信任、也无法真正上生产的。如何科学地评估一个 Agent 系统,正是那根**贯穿所有层的度量平面**——也是本系列**第⑦篇《评估工程:被忽略的第五根柱子》**要深入的内容。
我们下一篇见。
---
*本文为「企业 AI 化的四层工程体系」系列第 ⑥ 篇。至此,四层 runtime(Prompt → Context → Harness → Loop)已从内到外走完。但工程体系并未结束——接下来两篇,我们要讲那根贯穿所有层的度量平面(Eval),和那层让系统 7×24 连续运转的运营外壳(Relay)。*","createTime":1782738409,"ext":{"closeTextLink":0,"comment_ban":0,"description":"","focusRead":0},"favNum":0,"html":"","isOriginal":0,"likeNum":0,-
07.23
五行棋阵:混沌之境何时出 公测上线时间预告
-
07.23
遗忘之海船只养成攻略 遗忘之海船只改装强化全指南
-
07.23
我的仙侣日常何时出 公测上线时间预告
-
07.23
光遇7月22日季节蜡烛位置一览
-
07.23
饥困荒野毒菌蟾蜍打法攻略 饥困荒野高效击败毒菌蟾蜍技巧分享
-
07.23
光遇7月22日每日任务完成攻略
-
专题
三国战纪-风云再起 整合版
-
专题
三国战纪-乱世枭雄
-
-
下载
- |
-
-
下载
- 《行尸走肉第一章》免安装中文汉化硬盘版下载
- 单机|436 MB
- 一款以动作冒险为主题的游戏
-
-
下载
- 《街头霸王X铁拳》免安装中文汉化硬盘版下载
- 单机|111MB
- 一款非常好玩的格斗游戏
-
-
下载
- |
-
-
下载
- 《暗黑破坏神3》免安装繁体中文正式版下载
- 单机|7630 MB
- 一款以角色扮演为主题的游戏
-
-
下载
- 《马克思佩恩3》免安装硬盘版下载
- 单机|27033 MB
- 一款以第三人称射击为主题的游戏